The new Amazon Web Service Data Pipeline: Stakes, Opportunities ad Challenge for the companies
It is obvious that the increase or the range of multiple sources of data to process is getting more and more complex inside the companies, government and organizations.

The frequent
issues meet here include: Increasing Size, variety of formats, disparate
storage and Distributed, Scalable Processing.
Therefore
since November 29, 2012 Amazon Web Services has marked the step forward via the new Amazon Web Service Data Pipeline.
the concept of the Pipeline
here includes: a set of data sources, preconditions, destinations, processing
steps, and an operational schedule, all aims to be define in a Pipeline
Definition.
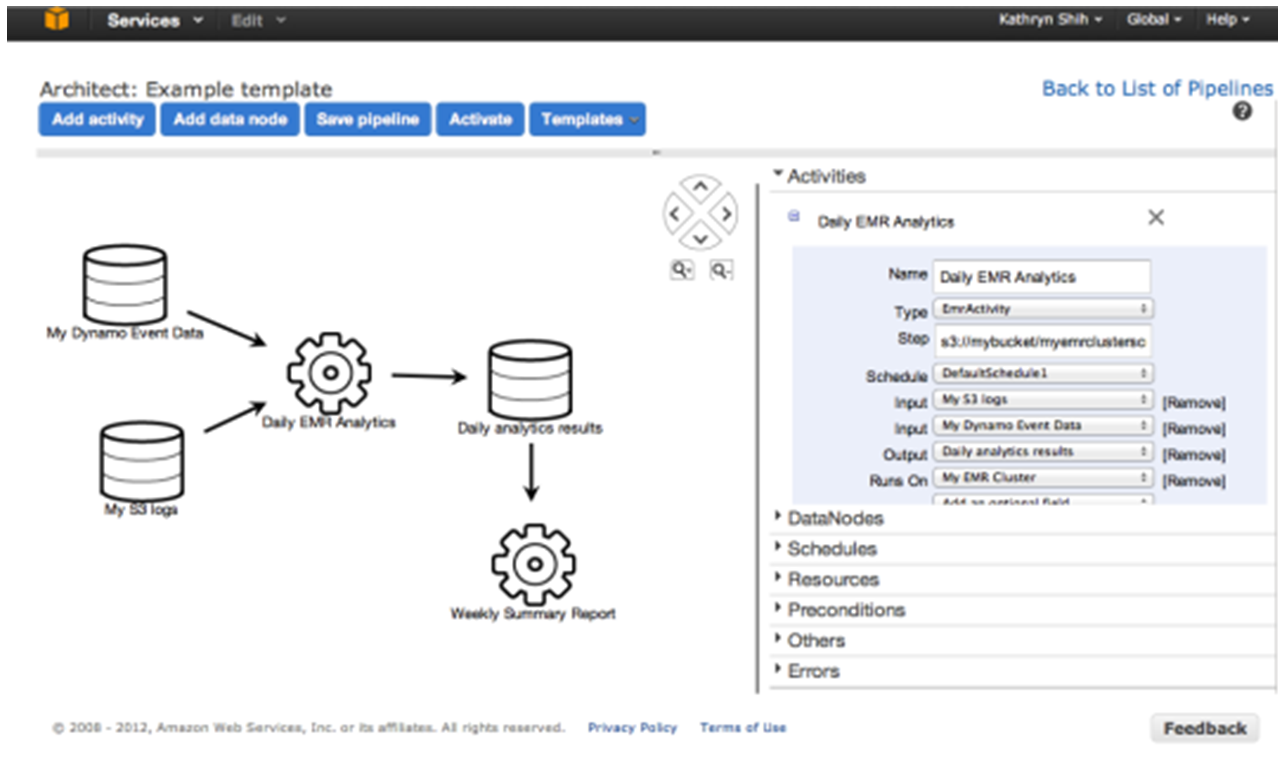
In fact the definition aims to
specify where the data comes from, what to do with it, and where to store it. This
also means that, once you define and activate a pipeline, it will run according
to a regular schedule. You could, for example, arrange to copy log files from a
cluster of Amazon EC2 instances to an S3 bucket every day, and then launch a
massively parallel data analysis job on an Elastic MapReduce cluster once a
week.etc.
You can create a Pipeline
Definition in the AWS Management Console or externally, in text form.
The AWS Data Pipeline is currently
in a limited private beta. In case of you are interested, you can contact AWS sales.

Comments